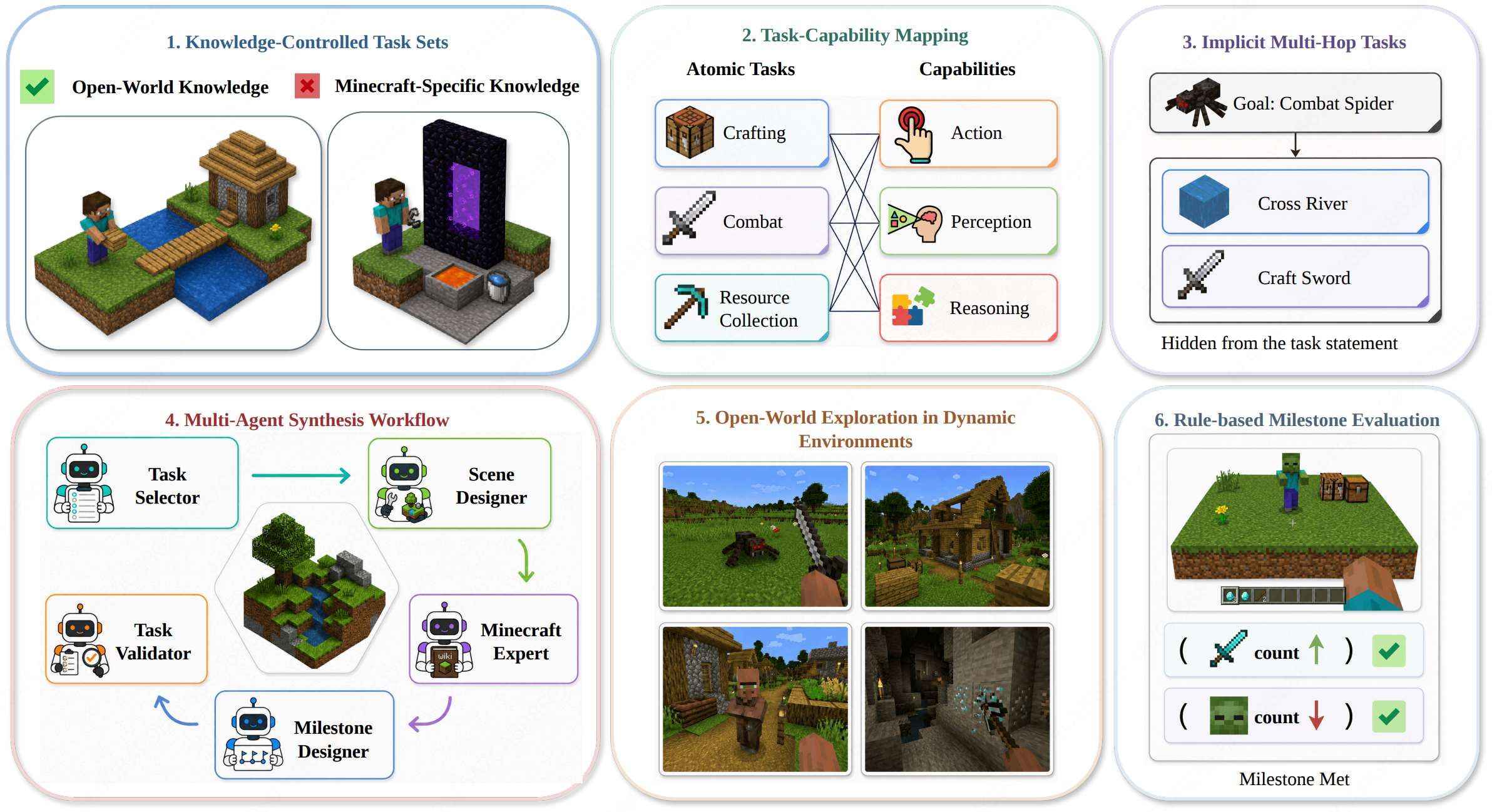
MineExplorer is a benchmark for evaluating the open-world exploration capabilities of multimodal large language model (MLLM) agents in Minecraft. We first filter atomic tasks whose solutions rely heavily on Minecraft-specific knowledge to better reflect general open-world reasoning, then organize the benchmark around a ReAct-style capability formulation and compose atomic tasks into implicit multi-hop tasks. To construct reliable instances, MineExplorer uses a multi-agent synthesis workflow that jointly designs task graphs, sandbox scenes, and rule-based milestone evaluators. Experiments show that open-world exploration remains challenging: strong models handle many single-hop tasks but degrade sharply when hidden prerequisites must be coordinated over longer trajectories, and larger models or thinking modes do not consistently translate into better performance.
MineExplorer uses a Minecraft sandbox service built on top of MineStudio, an open-source framework that provides a Minecraft simulator engine controllable via HTTP API. The sandbox allows you to programmatically create and control Minecraft game environments — spawning scenes, issuing commands, resetting episodes, and capturing first-person screenshots.
We release a ready-to-use Docker image: davidzhth/mineexplorer:0.0.1
| Component | Version / Details |
|---|---|
| Base OS | Ubuntu 22.04 |
| Python | 3.10 |
| Java | OpenJDK 8 (Minecraft runtime dependency) |
| Framework | MineStudio (bundled Minecraft simulator engine) |
| Rendering | Xvfb virtual framebuffer (headless rendering, no display required) |
docker run -d --name mineexplorer -p 8000:8000 davidzhth/mineexplorer:0.0.1The service listens on port 8000. On first launch, Minecraft needs to load the world — this typically takes 60–120 seconds. You can check readiness with:
curl http://localhost:8000/monitor/alive
# Returns: {"status":"alive", ...}Once the sandbox is running, set the following environment variable so that both generate_benchmark.py and eval_benchmark.py connect to it automatically:
export MC_SANDBOX_URL=http://localhost:8000You are then ready to generate and evaluate the benchmark as described in the sections below.
Install the required Python packages:
pip install gymnasium numpy requests pillow loguru python-dotenv typer fastapi uvicorn pydantic imageio imageio-ffmpegSet the required environment variables:
export AGENT_API_KEY="your_api_key"
export AGENT_API_BASE="https://your-api-endpoint/v1/openai/native"Use generate_benchmark.py to generate Minecraft evaluation tasks. The benchmark directory contains the benchmark used in the paper, covering single-hop to 4-hop tasks.
python generate_benchmark.py multi \
--model aws.claude-opus-4.6 \
--num-samples 10 \
--k-min 1 \
--k-max 1 \
--candidate-num 1 \
--output benchmark_new| Argument | Description |
|---|---|
multi / single |
Multi-agent or single-agent benchmark generation. The paper uses multi-agent mode, which produces more reliable instances but is slower due to sandbox interaction. |
--model |
Model name to use for generation |
--num-samples |
Number of samples to generate |
--k-min / --k-max |
Range of subtask hops per sample (e.g., set both to 1 for single-hop tasks only) |
--candidate-num |
Number of candidate atomic tasks |
--output |
Output directory |
benchmark_new/
├── 0000/
│ └── multi-agent/
│ ├── metadata.json # Scene configuration
│ ├── milestones.json # Milestone definitions
│ ├── reasoning_graph.json # Dependency graph
│ └── debate_log.json # Agent dialogue log
├── 0001/
│ └── multi-agent/
│ └── ...
You can generate extremely challenging tasks by increasing --k-min, --k-max, and --candidate-num. For example, the following command generates tasks with 8–12 prerequisite hops and 15 candidate atomic tasks:
python generate_benchmark.py multi \
--model aws.claude-opus-4.6 \
--num-samples 10 \
--k-min 8 \
--k-max 12 \
--candidate-num 15 \
--output benchmark_hardThis produces tasks with deeply nested, multi-branch dependency graphs — far more complex than standard benchmark instances:
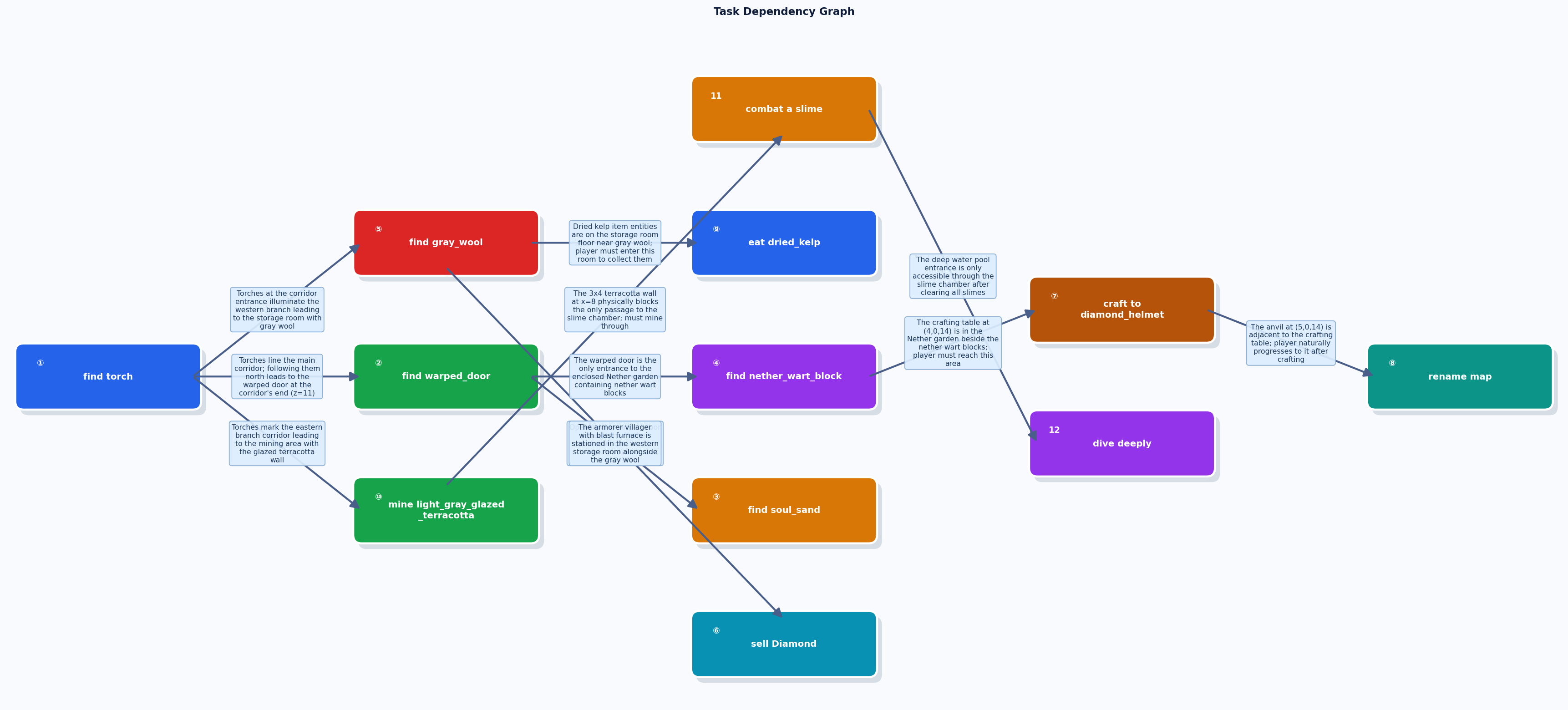
Use eval_benchmark.py to run an agent on the generated benchmark and evaluate its performance.
python eval_benchmark.py \
--model aws.claude-opus-4.6 \
--benchmark-dir benchmark_new \
--output-dir results \
--num-workers 10 \
--resumeStart the vLLM server first:
python -m vllm.entrypoints.openai.api_server \
--model Qwen2.5-7B \
--port 8000Then run evaluation:
python eval_benchmark.py \
--model Qwen2.5-7B \
--benchmark-dir benchmark_new \
--output-dir results \
--num-workers 10 \
--use-vllm| Argument | Description |
|---|---|
--model |
Model to use for evaluation |
--benchmark-dir |
Path to the benchmark directory |
--output-dir |
Directory to save results |
--num-workers |
Number of parallel sandbox workers |
--resume |
Resume from checkpoint (skip completed tasks) |
--limit |
Limit number of evaluation samples (for testing) |
results/
└── aws.claude-opus-4.6/
├── 0000/
│ ├── result.json # Evaluation result
│ ├── episode.mp4 # Episode replay video
│ └── messages/ # Conversation logs
├── 0001/
│ └── ...
└── eval_summary.json # Aggregated statistics
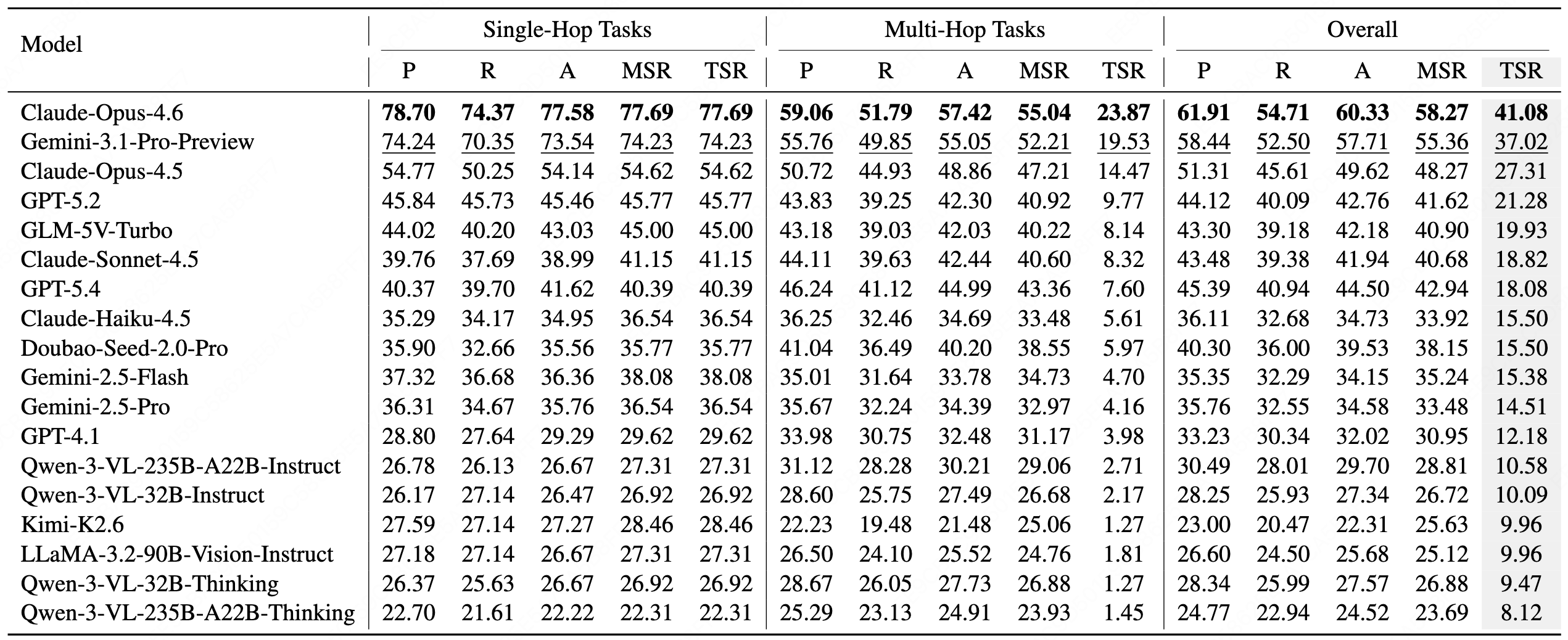
If you find this work useful, please cite:
@misc{ju2026mineexplorerevaluatingopenworldexploration,
title={MineExplorer: Evaluating Open-World Exploration of MLLM Agents in Minecraft},
author={Tianjie Ju and Yueqing Sun and Zheng Wu and Wei Zhang and Yaqi Huo and Xi Su and Qi Gu and Xunliang Cai and Gongshen Liu and Zhuosheng Zhang},
year={2026},
eprint={2605.30931},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2605.30931},
}This project is released under the MIT License.