




This is an unofficial PyTorch implementation of the Moises-Light architecture from "Moises-Light: Resource-efficient Band-split U-Net for Music Source Separation" (Hung et al., WASPAA 2025). The paper does not release code; this is an independent implementation based on the paper's description and the open-source implementations of DTTNet, BS-RoFormer, and SCNet.
pip install moises-lightpip install git+https://github.com/crlandsc/moises-light.gitOr, you can clone the repository and install it in editable mode for development:
git clone https://github.com/crlandsc/moises-light.git
cd moises-light
pip install -e .- PyTorch (>=2.0)
- einops
- rotary-embedding-torch
import torch
from moises_light import MoisesLight, configs
# Use a preset
model = MoisesLight(**configs['paper_large'])
# Forward pass
x = torch.randn(1, 2, 264600) # [batch, channels, samples] 6s @ 44.1kHz
y = model(x) # [1, 4, 2, 264600] = [batch, stems, channels, samples]
# With auxiliary outputs interface (for training framework compatibility)
y, aux = model(x, return_auxiliary_outputs=True)All presets use n_fft=6144, hop_size=1024, stereo input, and 4-stem output (vocals, drums, bass, other).
The paper truncates the STFT at 2048 bins (~14.7 kHz), zeroing everything above. While the original DTTNet paper noted that this truncation has little to no effect on SI-SDR scores, in practice these high frequencies are critical for perceptual audio quality — vocal air, cymbal shimmer, synth brightness, etc. all live above 15 kHz. This package includes fullband presets that extend processing to the full 0-22 kHz spectrum.
Extending to fullband requires increasing n_bands from 4 to 6 (to maintain 512 bins per band), and G must be divisible by n_bands for group convolutions. Since 56 is not divisible by 6, G must change. Two strategies are provided:
- Fullband matched-param — Pick the nearest valid G that keeps total params similar to the paper (G=60 or 36). This trades per-band capacity for full spectrum coverage within the same parameter budget. SI-SDR may decrease slightly since the same capacity is spread across 2 additional high-frequency bands.
- Fullband wide — Pick G so that
G/n_bandsmatches the paper's per-group channel count (84/6=14, matching 56/4=14). Each band retains the same representation power as the paper model, but total params increase ~1.8x. This may preserve metric performance while gaining full spectrum coverage.
Faithful to the paper's architecture. Frequencies above ~14.7 kHz are zeroed.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
paper_large |
56 | 4 | 14 | 0-14.7 kHz | 5,451,216 |
paper_small |
32 | 4 | 8 | 0-14.7 kHz | 2,558,768 |
Full spectrum via 6 bands of 512 bins (freq_dim=3072). G adjusted to keep param count close to paper variants.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
fullband_large |
60 | 6 | 10 | 0-22 kHz | 5,477,844 |
fullband_small |
36 | 6 | 6 | 0-22 kHz | 2,805,796 |
Full spectrum with the same per-group channel capacity as the paper models.
| Preset | G | Bands | Per-group ch | Freq coverage | Params |
|---|---|---|---|---|---|
fullband_large_wide |
84 | 6 | 14 | 0-22 kHz | 9,704,844 |
fullband_small_wide |
48 | 6 | 8 | 0-22 kHz | 4,323,976 |
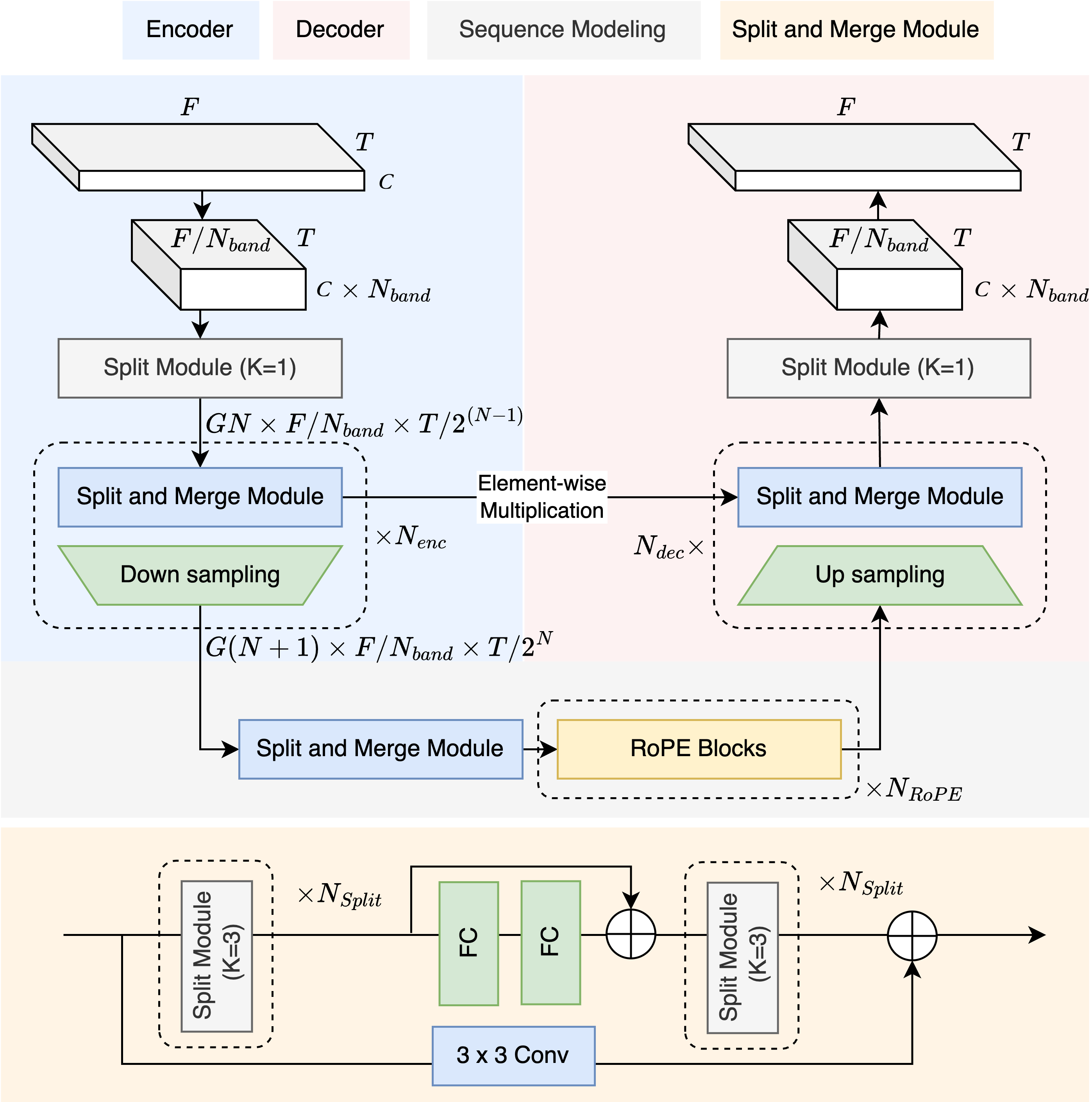
Moises-Light builds on the DTTNet foundation (a symmetric U-Net with TFC-TDF encoder/decoder blocks and dual-path RNN bottleneck) and integrates improvements from BS-RoFormer and SCNet:
- Band splitting via group convolutions (inspired by BSRNN/BS-RoFormer): Instead of DTTNet's full-spectrum convolutions, the STFT is divided into
n_bandsequal-width subbands and processed with group convolutions (Split Module). This replaces DTTNet's first/last 1x1 convolutions and dramatically reduces parameters compared to the original band-split MLPs in BSRNN. - Split and Merge Module (replaces DTTNet's TFC-TDF V3 blocks): Group conv blocks with
n_bandsgroups replace the original TFC layers, so each band is processed independently. The TDF (Time-Distributed Frequency FC) bottleneck is retained but now operates on per-band frequency dimensions (freq_dim / n_bands), which isn_bandstimes cheaper. - RoPE transformer bottleneck (from BS-RoFormer): DTTNet's dual-path RNN is replaced with dual-path RoPE transformers for sequence modeling along both frequency and time axes. This improves performance without significantly increasing parameters.
- Asymmetric encoder/decoder (from SCNet): The encoder has
n_encheavy stages (each with a full Split and Merge block), while the decoder uses onlyn_decheavy stages plusn_enc - n_declight stages (upsample + skip connection only, no Split and Merge). This saves significant compute in the decoder. - Frequency truncation (from DTTNet): Only
freq_dimof then_fft/2+1STFT bins are processed; the rest are zero-padded for iSTFT reconstruction. Paper presets truncate at ~14.7 kHz; fullband presets extend to ~22 kHz. - Multiplicative skip connections (from DTTNet): Decoder stages combine upsampled features with encoder skip connections via element-wise multiplication rather than concatenation or addition.
This is an independent implementation — the paper does not release code. The following decisions were made where the paper was ambiguous or where I diverged:
-
Asymmetric decoder interpretation: The paper specifies
N_enc=3, N_dec=1(Table 1) but doesn't explicitly state what happens with the remaining 2 decoder stages. I interpretN_dec=1as 1 heavy stage (with Split and Merge processing) and 2 light stages (upsample + skip connection only), matching the SCNet asymmetric pattern. -
Time-only downsampling: DTTNet downsamples both time and frequency dimensions (
T/2^NandF/2^N). Our implementation only downsamples time. The paper states that band-splitting "allows us to remove frequency pooling or upsampling across all DTTNet layers" (Sec 3.1), but doesn't explicitly confirm this removal in the final architecture. -
Transformer hyperparameters: The paper does not specify the RoPE transformer's internal dimensions. I use
heads=4, dim_head=32, ff_mult=2— chosen to keep the bottleneck lightweight and consistent with the model's parameter budget. -
Multiplicative masking: The paper states the model "directly generating the separated target spectrogram." By default (
use_mask=True), our implementation applies multiplicative masking on the original STFT (i.e., the network predicts a mask rather than the spectrogram directly). This is a common and effective approach in other SOTA models like BS-RoFormer and often leads to better perceptual quality, particularly for silent segments. Settinguse_mask=Falseswitches to the paper's direct spectrogram generation mode, where the network output produces spectrograms directly. -
Z-score normalization: The paper does not mention input normalization. I apply Z-score normalization (zero mean, unit variance) to the STFT features before the U-Net, inspired by HTDemucs-style preprocessing. This is standard practice in similar architectures and stabilizes training.
-
TDF bottleneck factor (
bn_factor): The paper does not specify this parameter. DTTNet usesbn_factor=8for vocals, drums, and other, andbn_factor=2for bass (bass has narrower frequency range and more tonal structure, benefiting from higher TDF capacity). This implementation defaults tobn_factor=8to match DTTNet's majority-stem setting. For single-stem bass models, considerbn_factor=2. -
Multi-stem output: The paper trains separate per-stem models (4x ~5M params for VDBO). This implementation outputs all stems simultaneously via a shared encoder and source head, as this paradigm has proven effective in other U-Net models like HTDemucs and SCNet. To reproduce the paper's approach, train 4 separate single-stem models (e.g.,
MoisesLight(sources=['vocals'])).
| Parameter | Description | Constraint |
|---|---|---|
G |
Base channel width. Channels at encoder stage i = G*(i+1) | Must be divisible by n_bands |
n_bands |
Number of equal-width frequency bands for group conv | freq_dim must be divisible by n_bands |
freq_dim |
Number of STFT bins to process (rest zero-padded) | Paper: 2048 (~~14.7 kHz). Fullband: 3072 (~~22 kHz) |
n_rope |
Number of dual-path RoPE transformer blocks in bottleneck | Paper large: 5, paper small: 6 |
n_enc / n_dec |
Encoder stages / heavy decoder stages | Asymmetric: n_dec < n_enc saves params |
n_split_enc / n_split_dec |
Number of group conv layers per SplitAndMerge block | Controls depth within each stage |
bn_factor |
TDF bottleneck factor (freq_dim -> freq_dim/bn_factor -> freq_dim) | Default: 8. DTTNet uses 2 for bass |
model = MoisesLight(**configs['paper_large'])
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-4)
for batch in dataloader:
mix = batch['mix'] # [B, 2, L]
targets = batch['targets'] # [B, 4, 2, L]
pred = model(mix) # [B, 4, 2, L]
loss = criterion(pred, targets)
loss.backward()
optimizer.step()
optimizer.zero_grad()- MPS (Apple Silicon): There is a bug in the MPS implementation of
torch.istft. The model automatically falls back to CPU for iSTFT when on MPS, which adds overhead. This is a PyTorch limitation, not a model issue. - Frequency truncation: Paper presets zero frequencies above ~14.7 kHz. Use fullband presets if high-frequency content matters.
@inproceedings{hung2025moises,
title={Moises-Light: Resource-efficient Band-split U-Net for Music Source Separation},
author={Hung, Yun-Ning and Pereira, Igor and Korzeniowski, Filip},
booktitle={2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)},
pages={1--5},
year={2025},
doi={10.1109/WASPAA66052.2025.11230925}
}Contributions are welcome! Please open an issue or submit a pull request if you have any bug fixes, improvements, or new features to suggest.
This project is licensed under the MIT License - see the LICENSE file for details.